
神舞幻想对话文本提取记录
挖坑之路
2018年我玩了神舞幻想之后,就开始喜欢上这游戏了,因为山海经题材还有唯美场景很吸引我,虽然剧情不尽人意,但是其他地方还是有优点的,然后我开始有兴趣去提取素材了,这游戏是UE4(虚幻4)引擎,要是在当年的话仅有几个提取工具,现在出了很多工具,提取也方便了。大部分都能提取模型、贴图、音频、文本等,我只对音频、人物素材和文本感兴趣,模型啥的基本用不到就丢弃了~而且也想试试整理游戏对话,做成文档书查阅,这样以后回顾文本就方便了!
提取完需要的素材后,我就碰到了难题,始终没找到游戏文本!不知道放哪里去了,后来有大佬告诉我在Designer/Text文件夹下,终于找到了!然后又有个问题……用文本编辑器打开后,看到的都是乱码……

如图所示,能看到一些英文代码,但中文部分变成了乱码。感觉不对劲啊,难道是加密了?我尝试转换了其他编码都无效,用UnrealLocres、UE4TextExtractor等文本提取工具都无法解出正常的编码文字,我只好去海外论坛寻找方法了,看看有没有大佬给出解决方案。
当时去了ZenHax,XeHax几个论坛看看,也有几个人在讨论提取,对于游戏文本好像没几个人关注,我后来也去发了帖子问问如何提取uasset文件的数据,有人告诉我uasset通常是贴图素材等,文本可以用十六进制查看,若是乱码可能无解了。看来没啥希望了,可能要放弃了……
后来我不断搜索,有个俄区论坛在尝试翻译这游戏,评论中也很多人期待着,我要不去发帖问问他们怎么提取的,于是回复问:“请问游戏文本是怎么提取的,有已经提取的文件吗?”当然我是用中文转换俄语发的,毕竟我也不会俄语,然后大佬直接简单粗暴丢给我处理好的文本,这也太简单粗暴了!
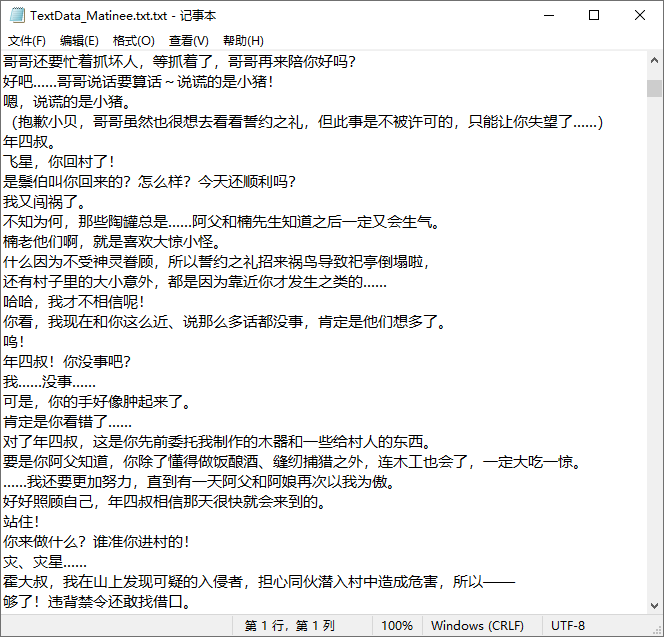
虽然是正确的文字,但是我想要源码诶……我也想看看原版代码是啥样,为什么他们能提取正常文字,而我提不出来!这不科学!!!留下了一堆疑问的我,我想继续问但是我不敢继续问了哈哈>﹏<就这么搁置了。
或许通过时间推移,我再慢慢搜索,一定能找到解决方法的!
再后来……
四年过去了,我无聊再去逛逛当时的帖子,发现大佬写了新的工具,诶!这回或许再次试试看?
尝试新的工具,这次居然成功了!!天哪!!!泪流满面!我终于能拿到正确的文本了!
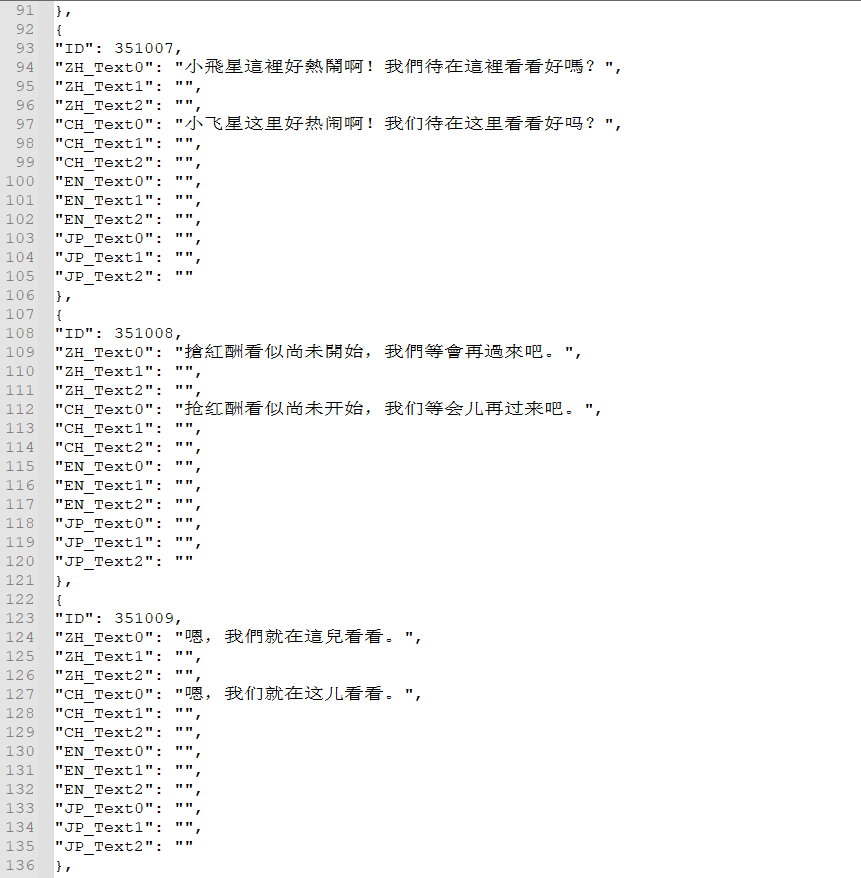
这就是我想要的源代码文本!!啊!!时隔四年才弄到正常文本,真是过了好久……_(:з)∠)_
不过现在也不晚,只要等着久一切皆有可能!
接下来就写个提取记录:
提取过程
可到 UE4localizationsTool Releases页面下载最新版本,该工具可以导出Locres、Uasset文本,双击exe程序可以打开图形化界面,打开uasset文件就可以看到文本了,点击 Tool > Export all text 可以导出txt文件。
我是使用了命令行,命令行方便点。
命令行:
UE4localizationsTool.exe export TextData_Matinee.uasset |
可选参数:
export <(Locres/Uasset) 文件导出路径>
import <(txt) 文件导入路径>
不过这工具没有批量命令,我自己写了批量bat,不用一个个写命令了。
for %%i in (*.uasset) do UE4localizationsTool.exe export %%i |
json批量转换excel
提取后仔细发现是个json格式的文本,可以导入excel制作成表格,一个文件处理还好,不过那么多文件要怎么批量处理呢?我去搜索了下有没有批量处理的方法,一搜果然搜到了!Python可以写个脚本做数据分析处理,果然Python是万能的,大部分都推荐安装pandas库,因为这个库处理方便,那我也来试试看~
需要安装:
Python 3.x
pandas库
可能还需要安装别的库,到时候按命令行窗口提示安装就好。
脚本代码:
#!/usr/bin/env python |
最后处理完后就变成这样了!是不是超级方便!

不过写遍历代码的时候也卡住灵感了,前面我放了out_file,最后在df.to_excel结尾加个out_file,是希望输出的时候全部都是xlsx格式,结果提示我代码不对!后来想了半天不如在后面加个”.xlsx”好了!居然成功了!噗看来我得多学习学习遍历知识,太久没写都忘了hhhh
pandas库只需要简单几个代码就能做到数据处理,真的超级方便!推荐你们使用~也有不用pandas的方法,但是还是不如pandas智能些。总之哪个方便就用哪个。
excel重复值差异对比替换人名
New 更新:突然想到神奇的操作,我可以用excel的条件格式来查找重复值就能一键输入角色名!早些年我听语音包自己标注了角色名,可以根据语音包的ID再和游戏文本的ID对比就能输入这些台词的人名了!
比如语音文件夹有分类单个角色的文件夹,可以用终端输入下面的命令,会把当前文件夹的所有文件名导出到xlsx表格。
DIR *.* /B >1.xls |
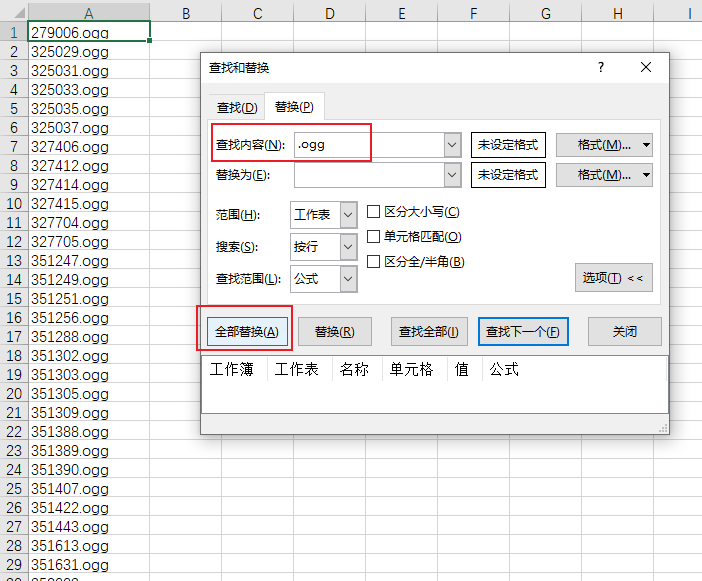
打开表格看到有后缀名.ogg,用查找替换把ogg删掉。
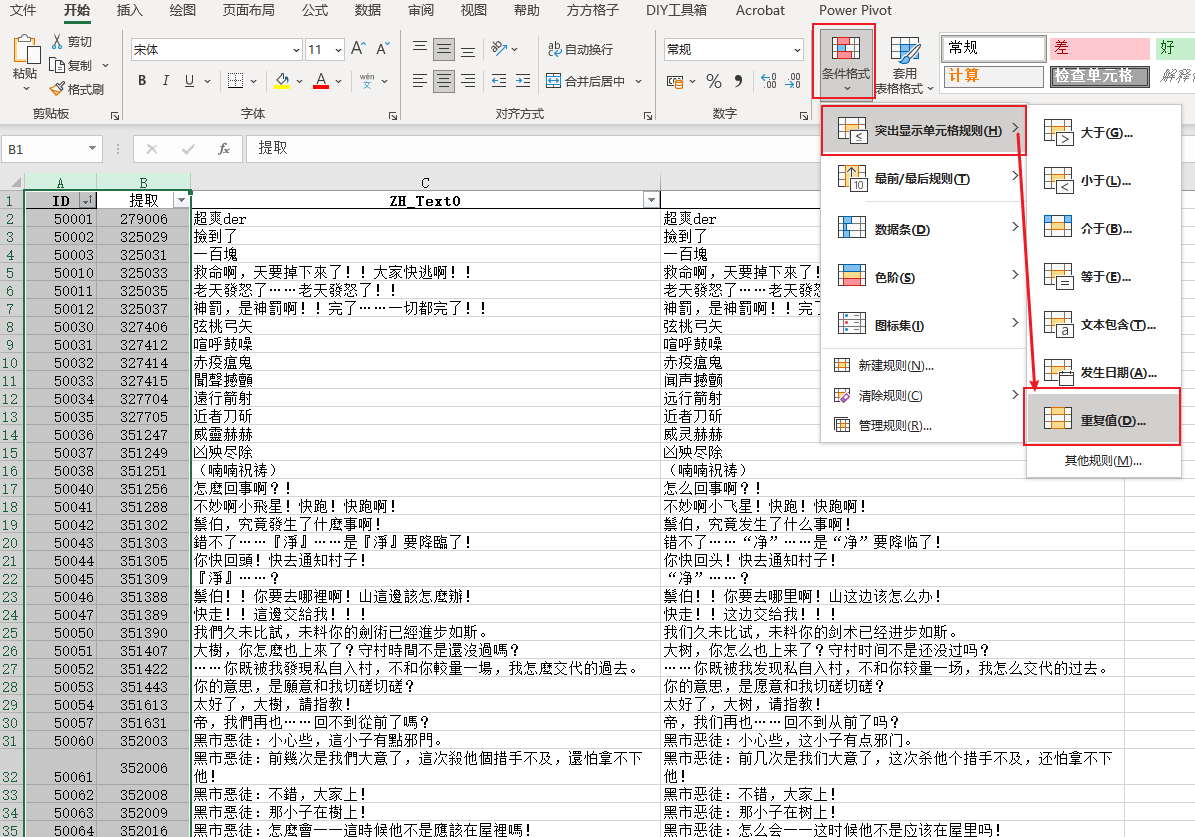
把语音ID列复制到游戏文本ID后面,选中两个列,在开始菜单点击 条件格式 > 突出显示单元格规则 > 重复值
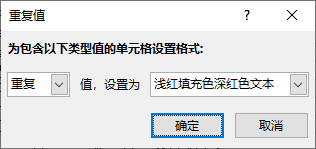
选择重复值即可,颜色可以选你喜欢的颜色。
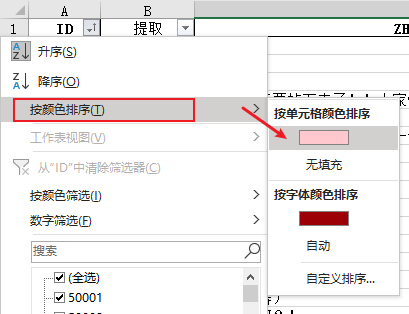
如果文本很长看不到标注的颜色,可以在ID列做下筛选,点击按颜色排序 > 刚才选的颜色就行,这样就能看到被标注颜色的单元格啦!
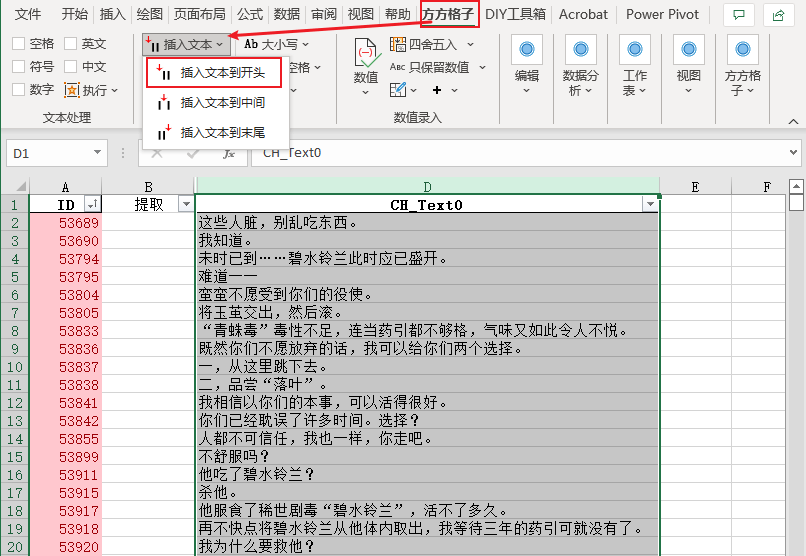
最后如果有安装了方方格子插件,在高级文本处理点击插入文本 > 插入文本到开头,就可以输入角色名了!
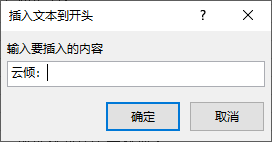
就此角色名键入成功!是不是很简单!这样能提高手打效率了哈哈哈哈~解放双手!果然科技是第一生产力啊!要多多活用呢!记得备份下源表格,以防失误做错步骤就可以重新从原来表格重做。
待续……
啊~这四年等了好久啊!其实主要是我能力不足吧,要不然能早点提取出来了……不过我也不是专业的程序员嘛,只对素材感兴趣,也是正常的!不过提取出来对话前面都没有人名,这个有点苦恼了……还得自己去手打,好麻烦哦!有时间再说吧,又是挖了一个坑……
其实制作组大部分都是幻想三国志的成员,现在他们回来制作了神舞幻想,可能还保留着当年的习惯吧,幻三我记得对话文本提取出来也是没有人名,不过对话顺序是正常的,不是颠倒的那就行。幻三我也还没有玩完呢,有时间再继续玩吧,若有机会整理出来对话文本,算是完成最大的心愿了,也不会留下遗憾了!
神舞从2017年12月22日到现在也差不多快四年多了,不知道今年会不会有神舞2的消息呢?真希望早点能玩到啊!去年发布了宣传片后就没消息了,希望今年7月嘉年华会有点消息,期待中……


如果遇到评论加载不出来,请不要担心,稍等一会儿,等待服务器后台修复即可,或者过一段时间来看看~